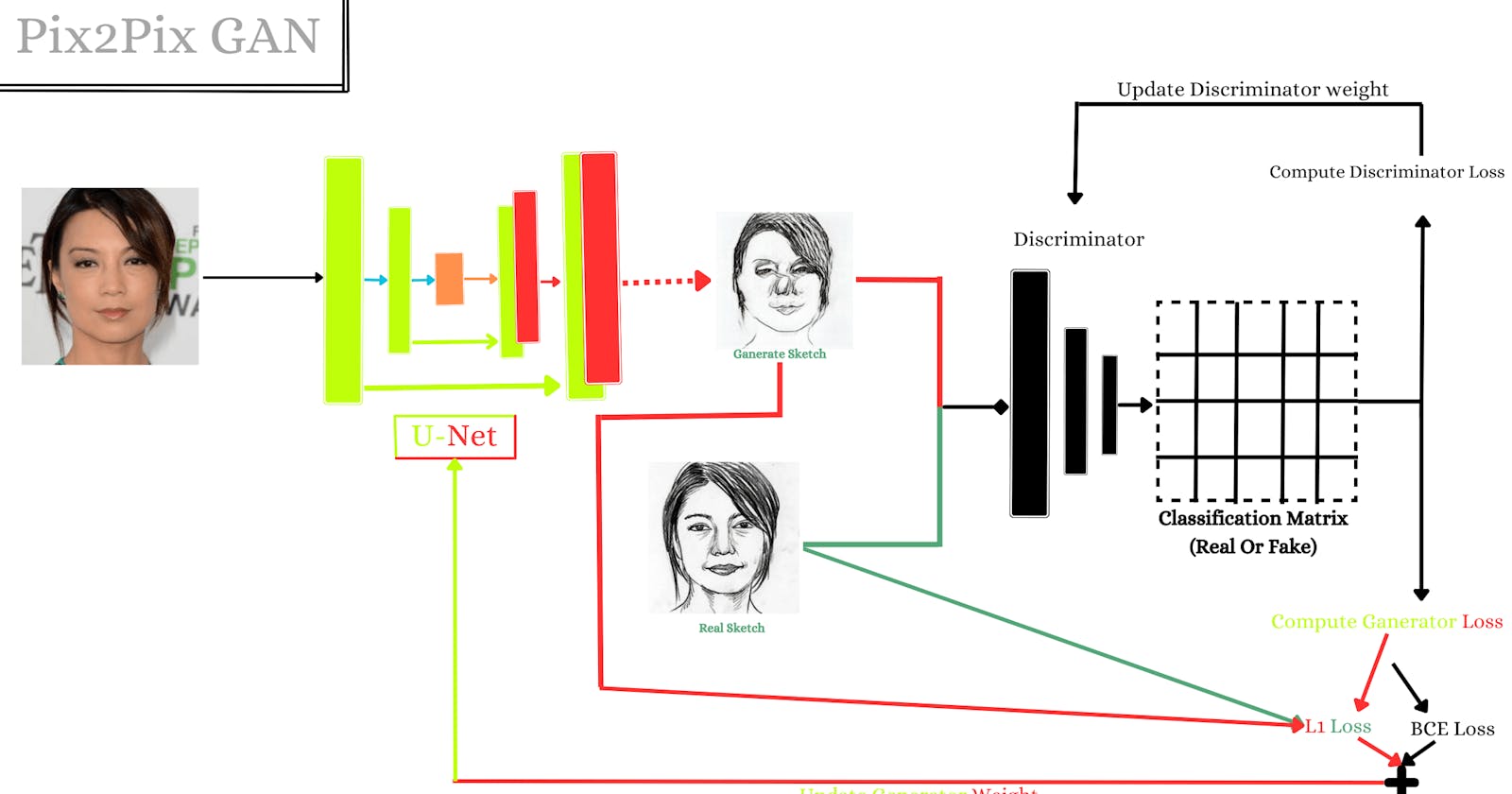


GAN is powerful once you know some techniques to train your model. So in this blog post, I share another GAN technique ( Pix2Pix ) that helps you train your model next level.
This is a full coding blog post, I believe learning by doing is the best way to learn something new.
Now let’s get started.
Pix2Pix is a generative adversarial network(GAN) technique that can convert images from one domain to another. It’s a really useful and powerful technique in GAN research. Pix2Pix can be used in many different places one of which is to turn photos into sketches. Pix2Pix works by training two neural networks a generator and a discriminator. The generator task is for creating the sketches, while the discriminator task is the opposite for distinguishing between real sketches and generated sketches. The two networks are trained together in a process called adversarial learning because they fight each other.
One real-world example of Pix2Pix that can be used is by fashion designers. Fashion designers use Pix2Pix to turn their sketches into realistic-looking photos of clothing. This can be helpful for designers who want to get feedback on their designs from clients or investors. This is only one example but this technique is used for a lot of areas.
# It's optional Comand to check If I using GPU
!nvidia-smi -L
# Output
# GPU 0: Tesla T4 (UUID: GPU-52db8cd6-0e29-5d03-f395-ffffa09f
Download Dataset From Kaggle
Intro For Dataset:
The FS2K dataset is the largest publicly available dataset for facial sketch synthesis. It consists of 2,104 image-sketch pairs, which were drawn by professional artists . The sketches in FS2K cover a wide range of image backgrounds, skin colors, sketch styles, and lighting conditions. In addition, the dataset also provides extra attributes, such as gender, smile, and hair condition, which can be used to train deep learning models.
Download Process to follow:
Go to the FS2K GitHub page.
Click the Google Drive link to download the dataset. Unzip the file using a file manager or the following code
!unzip FILE PATH
# Unzip the file followed by the command line
!unzip /content/drive/MyDrive/DL-Project/FaceToSketch/FS2K.zip
Preprocess The Dataset For Convert Right Shape
Data preprocessing is the process of cleaning and preparing data so that it can be used by a train in the Deep-Learning Model. This is important for image-to-sketch conversion because it can help to improve accuracy and performance.
Example:
One common data preprocessing task for image to sketch conversion is noise removal. This is because images often contain noise, such as speckles and graininess. This noise can interfere with the conversion algorithm, making it difficult to produce a smooth and accurate sketch. Noise removal techniques can be used to remove this noise so that the conversion algorithm can work more effectively.
In this process, I follow some of the things.
First, import some of the libraries for this project.
Then second load list of photo paths.
The third step is to create a custom dataset.
Fourth step using PyTorch DataLoader.
import os
import torch
from torch import nn
from torch.utils.data import Dataset , DataLoader ,ConcatDataset
from PIL import Image,ImageOps
import numpy as np
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
from torch import zeros,ones
from torch.optim import Adam
from torch.nn.init import normal_
from tqdm import tqdm
device = 'cuda' if torch.cuda.is_available() else "cpu"
print(device)
# Load the list of photo paths !
# My case dataset is based on 3 folders, so I load file paths into 3 different variables
# And also see that I am using os.listdir to get all file paths for the specific folder
photo1_path = os.listdir("/content/FS2K/photo/photo1/")
photo2_path = os.listdir("/content/FS2K/photo/photo2/")
photo3_path = os.listdir("/content/FS2K/photo/photo3/")
# See how many images each of these folders contain
len(photo1_path),len(photo2_path),len(photo3_path)
# Output (1529, 98, 477)
photo1_path[:5] # And also check if they are loaded properly
"""
Output
['image0624.jpg',
'image1383.jpg',
'image1497.jpg',
'image1587.jpg',
'image0851.jpg']
"""
Now the third and most exciting step is to create your own Custom dataset.
class CustomDataset(Dataset):
"""
CustomDataset class is a subclass of the Dataset class in PyTorch. This means that it can be used to create a dataset of images and sketches for training a machine learning model.
Args:
path_list (list of str): A list of paths to the image and sketch files.
src_path (str): The path to the directory where the image files are located.
dst_path (str): The path to the directory where the sketch files are located.
ext (str): The file extension of the image and sketch files.
image_size (int): The size of the images and sketches after they have been resized.
Returns: RGB photo and sketch image.
"""
def __init__(self,path_list,src_path,dst_path,ext='.jpg',image_size=(512,512)):
self.path_list = path_list
self.src_path = src_path
self.dst_path = dst_path
self.ext = ext
self.image_size = image_size
# This len method for return length of the dataset
def __len__(self):
return len(self.path_list)
# This is the most important method in this class.
def __getitem__(self,idx):
"""
Gets the image and sketch image at a particular index from the dataset.
Args:
idx: The index of the image and sketch to get.
Returns:
A tuple of the image and sketch tensors.
"""
# First join two path src folder and get path to the image file.
src_image_path = os.path.join(self.src_path,self.path_list[idx])
# and then check the extension of the file. and it requires a step because my dataset under have a
# multiple types of image extension files
if self.ext == '.png':
first_path = self.path_list[idx].replace('image','sketch')
dst_image_path = os.path.join(self.dst_path,first_path.replace('.jpg','.png'))
elif src_image_path.find(".JPG") != -1:
first_path = self.path_list[idx].replace('image','sketch')
dst_image_path = os.path.join(self.dst_path,first_path.replace(".JPG",'.jpg'))
else:
dst_image_path = os.path.join(self.dst_path,self.path_list[idx].replace('image','sketch'))
# Load the image and sketch from the filesystem.
src_img = Image.open(src_image_path).convert('RGB')
dst_img = Image.open(dst_image_path).convert('RGB'
)
# Resize the image and sketch to the specified size.
src_image = src_img.resize(self.image_size,Image.BILINEAR)
dst_image = dst_img.resize(self.image_size,Image.BILINEAR)
# Convert image to tensors and also normalize them
src_image = ((torch.from_numpy(np.array(src_image)).permute(2,0,1).float() ) - 127.5)/127.5
dst_image = ((torch.from_numpy(np.array(dst_image)).permute(2,0,1).float())- 127.5)/127.5
return src_image,dst_image
# Load the dataset in three variables because my dataset has three folders.
# And also make sure to pass through file extension.
train1_dataset = CustomDataset(photo1_path,"/content/FS2K/photo/photo1/","/content/FS2K/sketch/sketch1/")
train2_dataset = CustomDataset(photo2_path,'/content/FS2K/photo/photo2/','/content/FS2K/sketch/sketch2/',ext='.png')
train3_dataset = CustomDataset(photo3_path,'/content/FS2K/photo/photo3/','/content/FS2K/sketch/sketch3/',ext='.jpg')
# Check how many images have each of this dataset variable
print(f"First ds: {len(train1_dataset)},\
Second ds: {len(train2_dataset)},\
Third ds: {len(train3_dataset)}")
# Now time to combine three datasets to create one dataset for storing all images.
train_dataset = ConcatDataset([train1_dataset,train2_dataset,train3_dataset])
# also make sure to always check the length of the dataset.
print(f"Main Dataset Length: {len(train_dataset)}")
# If your dataset is ready. now time to move on and create a PyTorch DataLoader object.
train_loader = DataLoader(train_dataset, # It's actual dataset for create recently.
batch_size=1, # Batch size specify to how many image example model trains at the same time.
shuffle=True, # It's True which means the image gets randomly every time.
num_workers=4) # It spacifies to the number of subprocessors for use to load dataset.
#Output >>> First ds: 1529, Second ds: 98, Third ds: 477
Visualize Some Of The Examples
This time I write one function to display a batch of images. It’s very simple that only takes input as a batch of images, batch size, and the size of the image.
def show_tensor_images(image_tensor, num_images=25, size=(3, 32, 32)):
'''
Function for visualizing images: Given a tensor of images, number of images, and
size per image, plots and prints the images in a uniform grid.
'''
image_tensor = (image_tensor + 1) / 2.0 # Denormalize image
image_unflat = image_tensor.detach().cpu() # convert gpu to cpu
image_grid = make_grid(image_unflat[:num_images], nrow=1) # using as make grid function
plt.imshow(image_grid.permute(1, 2, 0).squeeze()) # convert image to right shape for require matplotlib
plt.show() # now time to showit
# In my case batch size 1. means only showing one image at a time.
# and it's also True value in shuffle parameter mean that every time different image show as.
for (src_images,dst_images) in tqdm(train_loader):
print(src_images.shape)
show_tensor_images(src_images)
show_tensor_images(dst_images)
break
Output >>> torch.Size([1, 3, 512, 512])

Create Discriminator Followed By Patch GAN
In that time I am using patched descriminator. If you don't know what it is don't worry I explained now.
Description:
First understand what is regular descriminator work. Regular discriminators take in an entire image and output whether it is real or fake. Patch discriminators, on the other hand, divide the image into smaller patches and evaluate each patch individually. This allows patch discriminators to be more efficient and accurate than regular discriminators, especially when you working with large dataset.
Real World explanation:
Suppose you are a painting detector and your job is to predict whether an image is real or fake. When you are trying to predict a new image, you must look at each part of the image to see if there are any inconsistencies. Similarly, a patch discriminator looks at each part of an image and returns whether it is real or fake.
Discriminator Architecture:
I follow this research paper to write Patch Discriminator
Architecture shape is mentioned in this above paper: C64-C128-C256-C512-C512-C512
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
# Weight initialization
self.conv1 = nn.Conv2d(6,64,(4,4),stride=(2,2),padding=1,bias=False)
self.act1 = nn.LeakyReLU(negative_slope=0.2)
self.conv2 = nn.Conv2d(64,128,(4,4),stride=(2,2),padding=1,bias=False)
self.bnorm1 = nn.BatchNorm2d(128)
self.act2 = nn.LeakyReLU(negative_slope=0.2)
self.conv3 = nn.Conv2d(128,256,(4,4),stride=(2,2),padding=1,bias=False)
self.bnorm2 = nn.BatchNorm2d(256)
self.act3 = nn.LeakyReLU(negative_slope=0.2)
self.conv4 = nn.Conv2d(256,512,(4,4),stride=(2,2),padding=1,bias=False)
self.bnorm3 = nn.BatchNorm2d(512)
self.act4 = nn.LeakyReLU(negative_slope=0.2)
self.conv5 = nn.Conv2d(512,512,(4,4),padding=1,bias=False)
self.bnorm4 = nn.BatchNorm2d(512)
self.act5 = nn.LeakyReLU(negative_slope=0.2)
self.conv6 = nn.Conv2d(512,3,(4,4),padding=1,bias=False)
self.patch_out = nn.Sigmoid()
# weight initializer all conv2d layer
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, mean=0.0, std=0.02)
def forward(self,s_img, t_img):
# Concatenate source image and target image
m_img = torch.cat((s_img,t_img),dim=1)
# C64: 4x4 kernel stride 2x2
x = self.act1(self.conv1(m_img))
# C128: 4x4 kernel stride 2x2
x = self.act2(self.bnorm1(self.conv2(x)))
# C256: 4x4 kernel stride 2x2
x = self.act3(self.bnorm2(self.conv3(x)))
# C512: 4x4 kernel stride 2x2
x = self.act4(self.bnorm3(self.conv4(x)))
# C512: 4x4 kernel stride 2x2
x = self.act5(self.bnorm4(self.conv5(x)))
# Patch Output
x = self.patch_out(self.conv6(x))
return x
# First create Discriminator model and then create DataParallel model to train fast.
disc = torch.nn.DataParallel(Discriminator().to(device))
print(disc) # Print Discriminator architecture
"""
# OUtput
DataParallel(
(module): Discriminator(
(conv1): Conv2d(6, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(act1): LeakyReLU(negative_slope=0.2)
(conv2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(bnorm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act2): LeakyReLU(negative_slope=0.2)
(conv3): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(bnorm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act3): LeakyReLU(negative_slope=0.2)
(conv4): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(bnorm3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act4): LeakyReLU(negative_slope=0.2)
(conv5): Conv2d(512, 512, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1), bias=False)
(bnorm4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act5): LeakyReLU(negative_slope=0.2)
(conv6): Conv2d(512, 3, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1), bias=False)
(patch_out): Sigmoid()
)
)
"""
Create a Generator Followed By U-Net Architecture

In this part, I create a neural network to generate sketch images. You can also use this neural network to train different datasets such as cityscape, sketch to color image, edges2shoes, etc.
This Generator is followed by U-Net architecture.
U-Net Description
The U-Net architecture is a convolutional neural network that is commonly used for image to segmentation mask. It is named after its characteristic U-shaped structure, which consists of two main paths: encoder and decoder.
Encoder
The encoder path is responsible for extracting features from the input image. It starts with a layer of convolutional filters, which is followed by a series of max pooling layers. The max pooling layers reduce the spatial size of the image, but they also increase the number of feature channels. This allows the network to learn more complex features from the image.
Decoder
The Decoder path is responsible for upsampling the features from the contracting path and combining them with the original input image. This allows the network to preserve the spatial information of the input image, which is important for image to segmentation. The expansive path is made up of a series of upsampling layers, which are followed by convolutional filters.
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
# Encoder Block: C64-C128-C256-C512-C512-C512-C512-C512
self.e1 = self.define_encoder_block(3,64,batchnorm=False)
self.e2 = self.define_encoder_block(64,128)
self.e3 = self.define_encoder_block(128,256)
self.e4 = self.define_encoder_block(256,512)
self.e5 = self.define_encoder_block(512,512)
self.e6 = self.define_encoder_block(512,512)
self.e7 = self.define_encoder_block(512,512)
# bottlenech, no batch norm, and ReLU
self.b = nn.Conv2d(512,512,(4,4),stride=(2,2),padding=1)
nn.init.normal_(self.b.weight, mean=0.0, std=0.02)
self.actb = nn.ReLU(inplace=True)
# Decoder block: CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
self.d1 = self.define_decoder_block(512,512)
self.act1 = nn.ReLU(inplace=True)
self.d2 = self.define_decoder_block(1024,512)
self.act2 = nn.ReLU(inplace=True)
self.d3 = self.define_decoder_block(1024,512)
self.act3 = nn.ReLU(inplace=True)
self.d4 = self.define_decoder_block(1024,512,dropout=False)
self.act4 = nn.ReLU(inplace=True)
self.d5 = self.define_decoder_block(1024,256,dropout=False)
self.act5 = nn.ReLU(inplace=True)
self.d6 = self.define_decoder_block(512,128,dropout=False)
self.act6 = nn.ReLU(inplace=True)
self.d7 = self.define_decoder_block(256,64,dropout=False)
self.act7 = nn.ReLU(inplace=True)
self.d8 = nn.ConvTranspose2d(128,3,(4,4),stride=(2,2),padding=1,bias=False)
nn.init.normal_(self.d8.weight, mean=0.0,std=0.02)
self.act8 = nn.Tanh()
def forward(self,x):
xe1 = self.e1(x)
xe2 = self.e2(xe1)
xe3 = self.e3(xe2)
xe4 = self.e4(xe3)
xe5 = self.e5(xe4)
xe6 = self.e6(xe5)
xe7 = self.e7(xe6)
b1 = self.actb(self.b(xe7))
xd8 = self.act1(torch.cat((self.d1(b1),xe7),dim=1))
xd9 = self.act2(torch.cat((self.d2(xd8),xe6),dim=1))
xd10 = self.act3(torch.cat((self.d3(xd9),xe5),dim=1))
xd11 = self.act4(torch.cat((self.d4(xd10),xe4),dim=1))
xd12 = self.act5(torch.cat((self.d5(xd11),xe3),dim=1))
xd13 = self.act6(torch.cat((self.d6(xd12),xe2),dim=1))
xd14 = self.act7(torch.cat((self.d7(xd13),xe1),dim=1))
xd15 = self.d8(xd14)
out_image = self.act8(xd15)
return xd15
def define_encoder_block(self,in_chan, n_filters, batchnorm=True):
""" Defines an encoder block for the Pix2Pix GAN.
Args:
in_chan: The number of input channels.
n_filters: The number of output channels.
batchnorm: Whether to use batch normalization.
Returns:
The encoder block.
"""
# Create a list to store the layers of the encoder block
layers = []
# Add the convolutional layer with the specified number of in channels and out channels.
conv_layer = nn.Conv2d(in_chan, n_filters, kernel_size=4, stride=2, padding=1, bias=False)
# also initialize the weight of the convulation layer.
nn.init.normal_(conv_layer.weight, mean=0.0, std=0.02)
layers.append(conv_layer)
# Conditionally add batch normalization because it does not require every encoder block
if batchnorm:
layers.append(nn.BatchNorm2d(n_filters))
# Add the LeakyReLU activation
layers.append(nn.LeakyReLU(0.2))
# Create a sequential block using the list of layers
encoder_block = nn.Sequential(*layers)
return encoder_block
def define_decoder_block(self,in_chan,out_chan,dropout=True):
""" Defines a decoder block for the Pix2Pix GAN.
Args:
in_chan: The number of input channels.
n_filters: The number of output channels.
dropout: Whether to use dropout.
Returns:
The decoder block.
"""
# Create a list to store the layers of the decoder block.
layers = []
# Add the transposed convolutional layer with the specified number of in channels and out channels.
g = nn.ConvTranspose2d(in_chan,out_chan,(4,4),stride=(2,2),padding=1,bias=False)
# Initalize the weight of the ConvtTranspose2d layer.
nn.init.normal_(g.weight, mean=0.0,std=0.02)
layers.append(g)
# Using batch norm for every block
g = nn.BatchNorm2d(out_chan)
layers.append(g)
# Conditionally add a dropout layer because it does not require every decoder block.
if dropout:
g = nn.Dropout(0.5)
layers.append(g)
return nn.Sequential(*layers)
# First create a Generator model and then create a DataParallel model to train fast.
pix_gen = torch.nn.DataParallel(Generator().to(device))
print(pix_gen) # Print Generator model architecture.
Output >>>
DataParallel(
(module): Generator(
(e1): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2)
)
(e2): Sequential(
(0): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(e3): Sequential(
(0): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(e4): Sequential(
(0): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(e5): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(e6): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(e7): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(b): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(actb): ReLU(inplace=True)
(d1): Sequential(
(0): ConvTranspose2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Dropout(p=0.5, inplace=False)
)
(act1): ReLU(inplace=True)
(d2): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Dropout(p=0.5, inplace=False)
)
(act2): ReLU(inplace=True)
(d3): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Dropout(p=0.5, inplace=False)
)
(act3): ReLU(inplace=True)
(d4): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(act4): ReLU(inplace=True)
(d5): Sequential(
(0): ConvTranspose2d(1024, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(act5): ReLU(inplace=True)
(d6): Sequential(
(0): ConvTranspose2d(512, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(act6): ReLU(inplace=True)
(d7): Sequential(
(0): ConvTranspose2d(256, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(act7): ReLU(inplace=True)
(d8): ConvTranspose2d(128, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(act8): Tanh()
)
)
Final Step — Train Pix2Pix Model
In this section, I train Pix2Pix GAN it’s very simple and easy to understand if you are familiar with my previous article Generate Anime Face With GAN. Now time to implement some of the hyparameter and then implement optimizer and loss function.
Let's say a little bit about what is doing these two models.
Discriminator — The discriminator's job is to take the target and generate an image to classify which one is real or fake.
Generator— The generator's job is to take an input image and generate a more realistic sketch image that will fool the discriminator.
In the end, if the discriminator cannot tell which image is real and which image is fake, then that means the generator is doing a good job of generating realistic images.
This simple term is to do nothing more, so please relax.
epoch = 10 # It's used for how many time the model train the entire dataset.
L1_lambda = 0.3 # It's order to control how much the generator focused on generating image similar to real.
learning_rate = 0.0002 # It's helping for how much model parameter update during training.
beta_value = (0.5,0.999) # It controls how much the optimizer remembers the previous gradient.
gen_opt = Adam(pix_gen.parameters(),lr=learning_rate,betas=beta_value) # Generator Optimizer
disc_opt = Adam(disc.parameters(),lr=learning_rate,betas=beta_value) # Discriminator Optimizer
bc_loss = nn.BCELoss() # Simple Binary-Crossentropy
m_loss = nn.L1Loss() # It helpful generator model little bit know what looks like target image.
for e in range(epoch): # first iterate number of epoch
for (src_images,dst_images) in tqdm(train_loader): # And then iterate batch input and target image
src_images = src_images.to(device) # Move tensor to specefic device
dst_images = dst_images.to(device) # same as to do above
# Train The Discriminator
# Reset the gradient of the model parameter
disc.zero_grad()
# First discriminator real data see.
real_pred = disc(src_images,dst_images)
# Compute the binary cross entropy loss between the discriminator's real predictions and a tensor of ones.
rb_loss = bc_loss(real_pred,torch.ones_like(real_pred))
# Fake Train
# Generate a fake example based on the src image.
fake_sample = pix_gen(src_images)
# Discriminator now to see fake data.
# and also .detach() method used to remove from the computation graph of the discriminator.
fake_pred = disc(src_images,fake_sample.detach())
# Now compute the binary-cross entropy loss between the discriminator's fake prediction and a tensor of zeros.
fb_loss = bc_loss(fake_pred,torch.zeros_like(fake_pred))
# Combine real loss and fake loss
d_loss = rb_loss + fb_loss
# Backpropagate the discriminator's loss through the model.
d_loss.backward()
# Update the parameters of the discriminator model using the Adam optimizer.
disc_opt.step()
# Train the Generator
# Rest the Generator model parameter similar to discriminator
gen_opt.zero_grad()
# Discriminator takes an src and generates images and returns a prediction if it's real or not.
fake_pred2 = disc(src_images,fake_sample)
# Compute the binary-cross entropy loss between discriminator fake prediction and tensor of ones.
gb_loss = bc_loss(fake_pred2,torch.ones_like(fake_pred2))
# And also calculate L1 loss for the model to see the difference between generated and target image.
gm_loss = m_loss(fake_sample,dst_images)
# Combine these two losses and l1_lambda add to control the weight of the L1 loss.
g_loss = gb_loss + L1_lambda*gm_loss
# Backpropagate the generator loss through the model
g_loss.backward()
# Update the generator parameter for using Adam optimizer.
gen_opt.step()
print(f"Epoch: {e}")
# Every epoch after displaying the source, target, and generate images.
show_tensor_images(src_images,num_images=1)
show_tensor_images(dst_images,num_images=1)
show_tensor_images(fake_sample ,num_images=1)
# If the display image is complete then move on to save the model locally.
torch.save(pix_gen.state_dict(),"/content/drive/MyDrive/DL-Project/FaceToSketch/Artist.pth")
torch.save(disc.state_dict(),'/content/drive/MyDrive/DL-Project/FaceToSketch/Classifier.pth')


Thanks for your time reading this article, I hope you found some value If you have any questions or suggestions in this article comment now below or you can use my Twitter or Linkedin profile to directly message me. I am always looking to help someone who is curious about learning. Never think asking questions is a stupid thing.